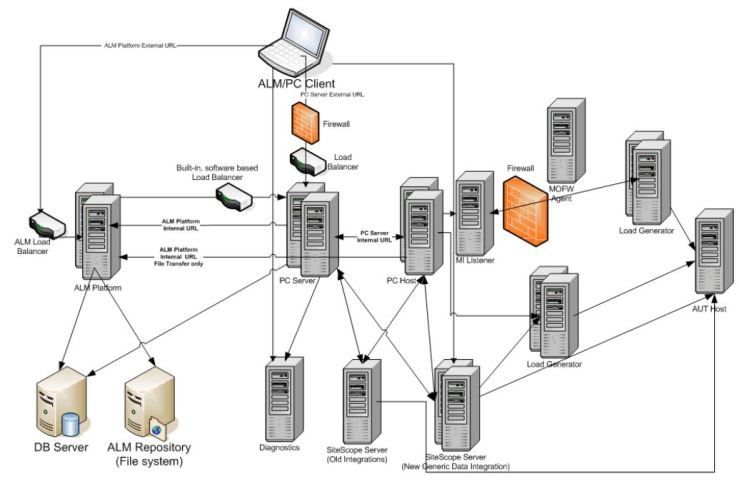
HPE has made some pretty drastic changes to the licensing model in the last 2 years. The the model takes what was once effectively free to a very expensive paid model. The new and currently supported version of SS (11.3X) only allows 25 systems to be monitored without additional paid licensing. It must be said that you have unlimited monitoring of counters within those 25 systems but you are restricted to a total of 25 systems. HPE has conveniently made it very painful to stay on 11.2X by removing support for it later this calendar year. Knowing that all major corporations will upgrade due to fear alone due to patch support – everyone will shift to 11.3X unless they are willing to pay for extended support.
With that in mind there are a few options:
- I don’t see anything in the license agreement that prevents you from running multiple instances of SS using the LoadRunner / Performance Center license. While this does cost more in Server hardware it does avoid the license costs.
- Maximize internal monitoring within LoadRunner / Performance Center when possible, especially for Windows based systems.
- Engage Server and Support Teams within your organization to pull monitoring data via other tools that are supported in the organization. Most large organizations have a set or sets of additional tools that pull similar data to SS.
- Evaluate options that exist with the competition. If HPE has a tool out there, there is more than likely someone else that has something similar at a cheaper rate. The trick is to find if it will fit well with your organization and your implementation of HP LoadRunner / Performance Center.
- Get creative with the monitoring… While 25 OSI license won’t cover large platforms, it might be enough for you to focus on a smattering of key systems on the platform. Less than ideal, but in a pinch it would give you a higher level of confidence than going without.
- Engage each team and request them to monitor their system(s) while the performance test executes. This is makes each performance test cost a lot more due to the effort involved but could be a short-term work-around.
Let me know if you have exposure to other monitoring solutions that work well within HP LoadRunner / Performance Center. I’ll be researching this independently and will report back on my next post.